Information Management and Preservation
Information and Software Engineering Group (IFS)Institute of Software Technology and Interactive Systems (ISIS)
Vienna University of Technology
Text Mining and Text Retrieval
Text Mining applies Data Mining methods to text documents. The goal is to uncover higher-level information, such as topics of documents, similarity between documents, etc. To this end, text mining applies methods for indexing and feature extraction, and supervised and unsupervised machine learning methods for collection organisation and document classification.
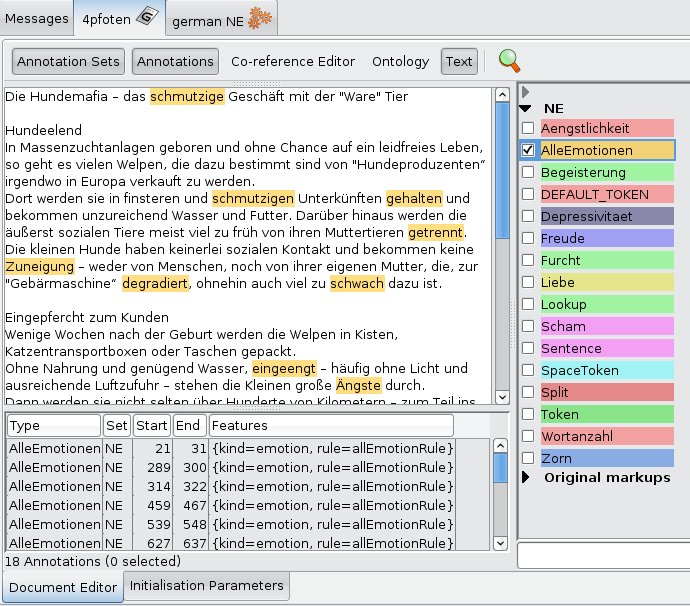
Emotion Mining
One of our latest projects in this area deals deals with the search for emotionality in text. Not every text which has to be objective meets this requirements. To asses the emotional content of text documents, we implemented an eomotionality measurement method for German language texts.
Patent Retrieval
Patents are special types of text documents - they exhibit certain properties that distinguish them from e.g. newspaper articles. Patents must comply to certain restrictions regarding their structure, with mandatory and optional sections. Further, they use a rather legislative language, and contain many inter-document references. Additionally, patents may also contain images and drawings.

Findability
Most information retrieval settings, such as web search, are typically precision-oriented, i.e. they focus on retrieving a small number of highly relevant documents. However, in specific domains, such as patent retrieval or law, recall becomes more relevant than precision: in these cases the goal is to find all relevant documents. This raises important questions with respect to retrievability and search engine bias: depending on the similarity measure and retrieval model, certain documents may be more or less retrievable, while some documents not being retrievable at all within common threshold settings. Biases may be oriented towards popularity of documents (increasing weight of references), towards length of documents, favour the use of rare or common words; rely on structural information such as metadata or headings, etc. We investigate an improved accessibility measurement by considering sets of relevant and irrelevant queries for each document. This simulates how recall oriented users create their queries when searching for relevant information.
Music Information Retrieval
Music Information Retrieval deals with ways of organising and accessing large collections of music. Important aspects are audio feature extraction, to capture characteristics of the musical pieces such as instrumentation, rhythm, chords, etc., as well as classification, clustering, and other means of organisation. A small selection of research topics is outlined below; more detailed information can be found on our dedicated Music Information Retrieval Website.
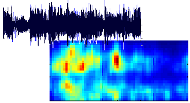
Audio Feature Analysis
We are researching advanced methods for extracting semantic information from music, such as rhythm, presence of voice, timbre, etc, using digital signal processing and psycho-acoustics. These feature extraction algorithms are the basis to many subsequent tasks, like automatic music categorization and organization.
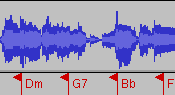
Audio Chord Detection
We developed a chord detection algorithm incorporating music theoretical knowledge in the form of key detection, beat tracking and chord-change frequencies improving the detection of chords in audio without restricting it to a narrow range of applicable music styles.
Music Classification
Applying machine learning methods and employing the features calculated from audio signal analysis we built a system performing categorization of music pieces into a pre-defined taxonomy, corresponding to the user's likes. The system has to be trained with a number of examples and is then able to categorize music into different classes, e.g. music genres (classical, jazz, hip hop, electronic, ...) or also identify artists. We also investigate combination of textual with audio information for music classification, and the recognition of moods and emotions in music.

Information Exploration
The MediaSquare - 3D Multimedia Environment
We developed a 3D Multimedia environment where users are impersonated as avatars enabling them to browse and experience multimedia content by literally walking through it. Users may engage in conversations with other members of the community, exchange experiences or simply enjoy the featured content.

SOM Racer - interactive music explorer
SOMRacer combines the functionality of the PlaySOM and PocketSOMPlayer applications with the look-and-feel of the classic open-source game TUX Racer. Self Organizing Maps serve as three-dimensional music landscapes, which can be explored by the player. The collected music tracks are exported as playlist.
Map of Mozart / Mnemonic SOM
The mnemonic SOM is an adaption of the original SOM algorithm that utilisizes non-rectangular shapes. The idea is to present
to the user shapes, such as country or continent maps, or geometrical shapes such as icons, he is familiar with, to provide an
additional mnemonic clue for remembering the locations and relationships between clusters.
In an application, wWe
extracted acoustic descriptors from the complete works of Wolfgang Amadeus Mozart and created an interactive Map of Mozart.
The map provides an immediate overview of all works by Mozart in an innovative way that catches the users attention.

Lib Viewer
The cover of a book, the title, type of binding, the shape of the binding (brand new versus well-used and almost torn apart), the size of the book, color and other properties of an item on the shelve contain a wealth of information that most people are accustomed to and able to interpret intuitively. Thus it is easy for us to gain an intuitive overview of the contents of a library and the type of information present. The libViewer system provides an intuitive user interface to a digital library by providing a graphical interpretation of metadata. Documents are assigned a physical representation template such as books, binders, papers etc., with further metadata such as language, date of last reference etc. being encoded by a set of additional metaphors such as the thickness of documents, dust, fingerprints, logos and spiderwebs.
Meta Viewer
Most of today's search engines still provide search results as a list of textual entries. The available information on the internet is increasing rapidly. A growing number of result sets for a given search text can soon become unwieldy. Using some sort of visualization could help the user analyzing the returned results. To make information visible contained in the metadata of results, graphical metaphors can be used for visualization. Taking the original concept of the libViewer one step further, the Metaviewer as its successor provides a more generic concept of maping metadata to a range of graphical attributes.
