
Institute of Software Technology and Interactive Systems
Information & Software Engineering Group
Music Information Retrieval
Tool Support for Acoustic Evaluation of Music Similarity
The evaluation of the ability of similarity measures between pieces of music is a non-trivial, sophisticated task because human cognition of music and perception of similarity inherently is biased by subjective interpretation and reasoning which usually is based on knowledge and conventions of the real world. Even songs belonging to the same genre, having a similar structure might be recognized as completely dissimilar by human cognition. Therefore, the evaluation of similarity between music tracks typically requires human judgment.
We present a novel tool called cLynx which offers several different features for an efficient acoustic evaluation of music similarity and additionally enables exploring and analyzing structured audio repositories much faster and more efficiently. An evaluation based on a listening test studies the applicability of this tool in various listening situations by highlighting trends in the subjects' perceptions and analyses connections between subjective interpretation and individual preferences and the subjects' perception of music similarity and susceptibility to outlier detection.
cLynx: A Novel Form of Music Similarity Evaluation
cLynx aims at supporting users in acoustic evaluation of audio-based music similarity measures. The application offers the evaluators several different approaches for accessing the underlying data of similarity systems in order to help them discovering similarities within audio data much faster and more efficiently. The tool can be used both with retrieval-based and cluster-based music similarity systems.
Several different mixer types assist the evaluators in exploring the data in order to get a meaningful overview of the underlying data's structure which allows them to detect whether a result set or cluster consists of homogeneous or heterogeneous data, e.g. outlier detection. For clustering based applications, such as PlaySOM, an additional mixer that incorporates information about spatial organization in the audio output is included.
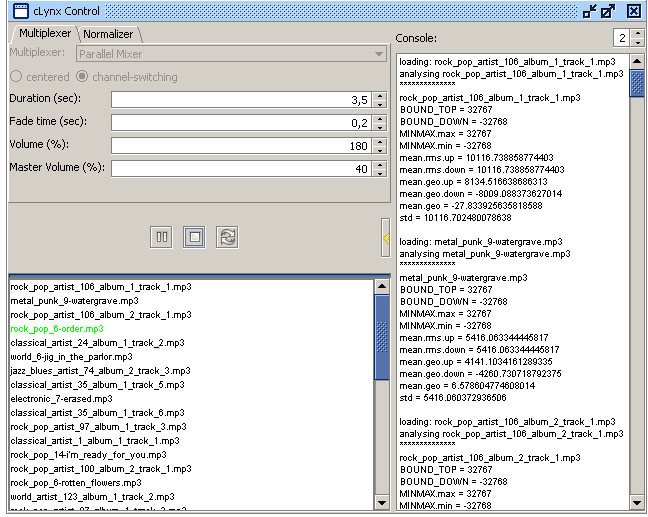
Algorithm
cLynx' applications flow is comprised of the following steps:
- Analysis
- Normalization
- Mixing
The Normalization process tries to combine the reduction of the dynamic range and the smoothing of the dynamic in order to get nearly equal volume levels for all pieces of music. Only when the dynamic range and the dynamic of all audio signals are nearly equal, the volume will not strongly differ. Therefore, during the normalization process the volume level of every single audio signal is modified. According to the selected type of normalization the sample values are mapped in a linear or dynamic way. Currently, a Linear Amplitude Normalizer and a Compressor are implemented. In contrast to the analysis step the normalization component is not a secluded process but directly interacts with the mixer process. All samples are normalized in runtime directly before they are sent through the mixer to the output device. This enables changing several normalization parameters in runtime.
The Mixer component represents the core of cLynx. It mixes all audio signals and multiplexes them to one single output signal. The mixer process is responsible to present the listener a clear and significant mix-down of all audio files which are part of the current empirical evaluation in a way that the user is able to create an acoustic association of a specified result set or cluster structure. According to the individuality of the human auditory sense and the differences in people's ability of absorbing and filtering information several different mixer components are implemented. The mixer step tackles the issue from three different angles:
- sequential playback (static and dynamic)
- parallel playback (static and dynamic)
- playback using 2D information
Mixer Types
Static Sequential Mixer (SSM):
merges all input signals sequentially into one single output signal.
Every audio signal is played back alone in all available channels for a
specified number of seconds (definable interactively by the duration
parameter), followed by another signal. The cross-over from one track
to its successor can be performed by a soft or hard changeover
(controlled by the fadeTime
parameter).
While at
first sight this mixer entails a rather long evaluation process its
duration is possibly reduced due to the continued switching from one
track to the next one within short time. Thus, the evaluator
potentially gets a quicker overview of the tracks under evaluation than
having to listen through the entire files sequentially.
| Dynamic Sequential Mixer (DSM): creates an output signal by passing different input signals to the available channels. It enables a kind of hearing tracks in parallel because the same number of tracks as channels are available is hearable at the same time but still it performs a sequential playback on every channel. The figure to the right illustrates how the Dynamic Sequential Mixer works. After track T1 was played back in the first channel and track T2 was played back in the second channel for a defined number of seconds, T2 is switched to channel1 and T3 to channel2. The changeover from T2 to the first channel, T3 to the second channel and the removing of T1 is performed using fading techniques. The total time for playback of a set of audio files under evaluation is the total duration of files divided by the number of available channels. Thus, this mixer aims at a reduced evaluation time while keeping the cognitive effort low. | 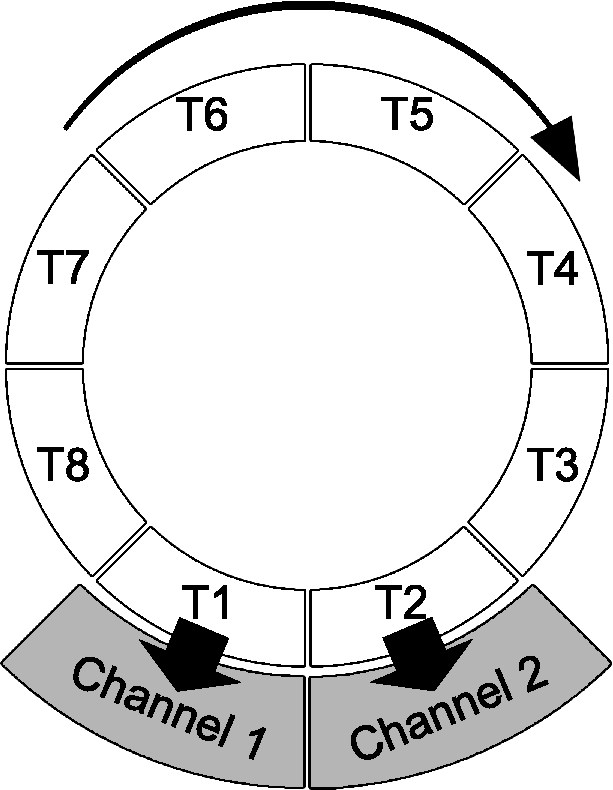 |
Static Parallel Mixer (SPM): creates an output signal by mixing all input signals simultaneously. Every audio track is played back in all channels together with all other signals. The Static Parallel Mixer represents one of the fastest mixers according to playback and evaluation time which results in demanding a high degree of concentration of the listeners. Although it may be impossible to recognize single tracks, the mixer can give a quick and rough overview whether the audio tracks in a playlist (or a cluster) are coherent or not. In highly heterogeneous sets containing a large number of songs the expressiveness is rather limited, while in nearly homogeneous sets a quick detection of outliers is feasible.
Dynamic Parallel Mixer (DPM): creates an output signal by mixing all input signals in parallel but with a changing weight. Every audio signal is played back in all channels together with all other signals but by contrast to the Static Parallel Mixer, one audio signal is played back louder for a defined duration. Therefore, it is easier for the listener to perceive individual tracks while at the same time getting a grasp of the entire set's audio content. In order to zoom out the track currently played louder two volume parameters can be specified: the masterVolume of all signals and the volume of the individually highlighted track, specified as percentage of the original value added to the master volume. DPM is intended to combine the advantages of parallel playback with those of sequential playback.
Spatial Mixer (SM):
creates an output signal on the basis of 2-dimensional spatial information
provided with the input signals. This is
possible with cluster, map, graph or other visualization based music
applications, which are able to provide location coordinates via an
interface (e.g. PlaySOM). Basically,
every signal is represented by a data point (coordinates) on a plane.
The listener is located in the origin of
the coordinate system. The signal's distance to the origin (listener)
is expressed by its volume level so that the volume level of a signal
decreases with increasing distance to the origin. A 2 and a 4 channel
setting is supported. Every audio signal is played back in a
specific
channel with a specific volume level, depending on location and
distance.
As for the
other parallel mixers the playback time is very short which also
requires a high degree of concentration, but allows a fast evaluation.
The
Spatial Mixer also presents an acoustic overview of the underlying set
of audio files, yet compared to the other parallel mixers the most
detailed one as it
considers relative similarity. That
allows the evaluator to recognize if a possible outlier is located
rather in the center or the boundaries of the area.
Run-time Modes
The cLynx tool can be executed in several different run-time Modes. The application flow within cLynx will not highly differ between the different modes. The two main modes are represented by the:
- Stand-Alone Mode
- Plug-In Mode
- Console Mode
- GUI Mode
User Study
The user study, which is discussed in the following paragraphs, was performed based on the tool cLynx using PlaySOM as the underlying music clustering application providing input. The key goal of this first study was to analyze the human cognition of music and the subjective interpretation of audio data according to different listening conditions simulated by the various mixer components of cLynx. The human's ability of filtering music (e.g. outlier detection) and judging music similarity and the subjective level of listening enjoyment according to sequential and parallel music playback were evaluated in order to conclude preferred mixer types for different types of music and various application scenarios.
The study used a music map that visualizes the ISMIR 2004 genre collection.
Voice detection
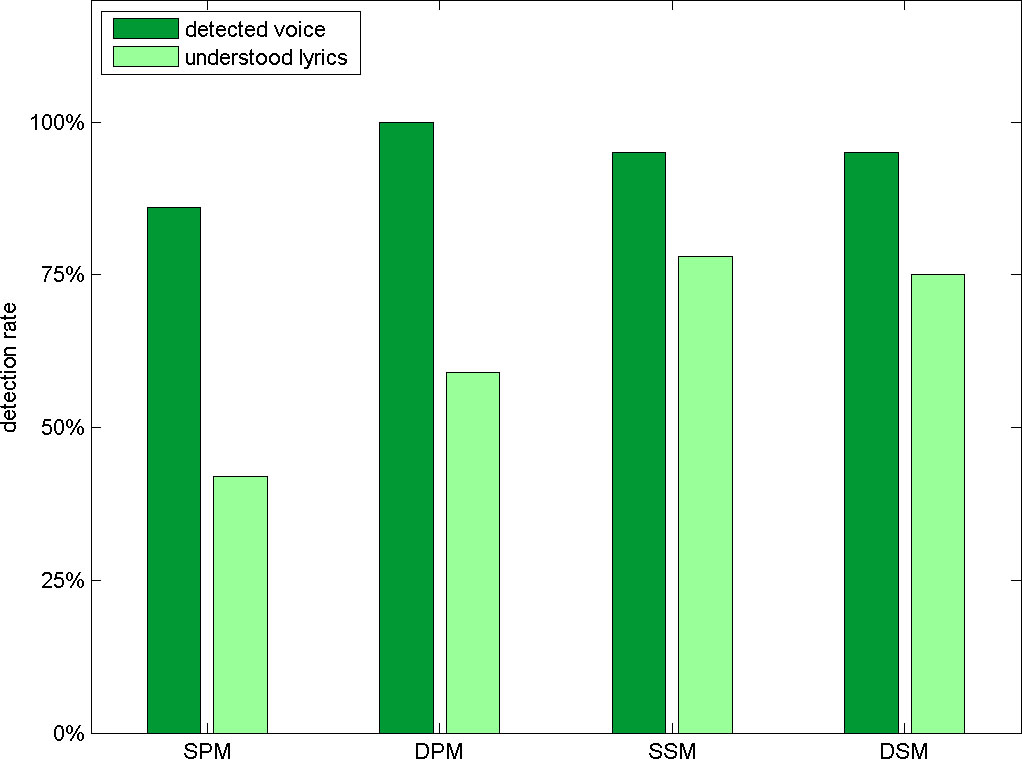
This plot shows that nearly all subjects recognized existing singing components irrespective of the type of used mixer component. In contrast to the high degree of correct voice identification over all listening situations only few subjects were able to get the lyrics when using a Parallel Mixer instance. The degree of understanding is much higher when using one of the Sequential Mixer components.
Track number estimation
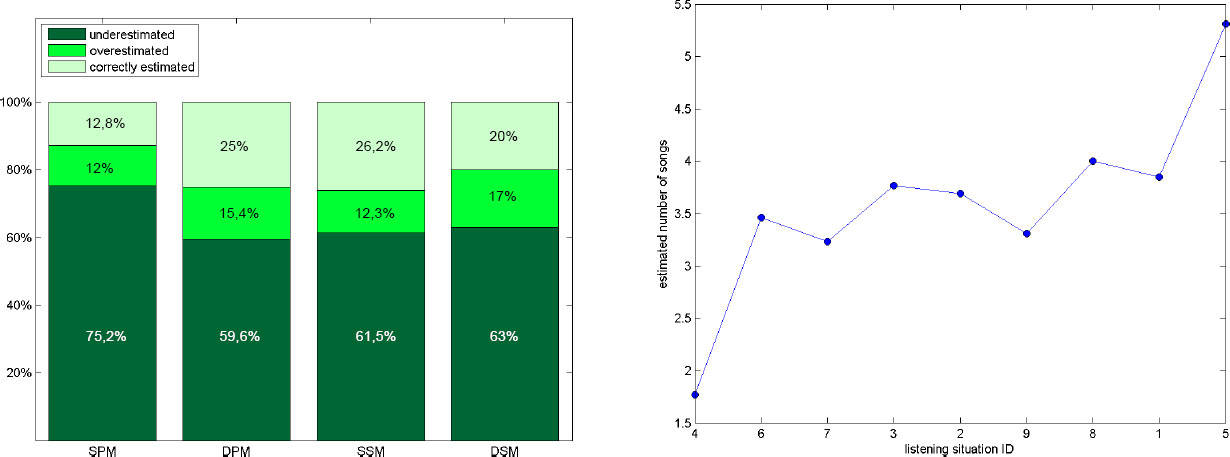
A very difficult task for all subjects was estimating the perceived number of tracks during one listening situation. Interestingly subjects only seldom thought of having listened to more songs than it actually was. Only three subjects thought of having listened to more than 10 songs during a parallel playback scenario. The subjects estimated 72% of all possible ratings smaller than 6 although only 47% definitely were. This result especially diverged for listening situations using the Static Parallel Mixer, where only 44% of the regions contained fewer songs than 6. Anyway, the subjects estimated 84% of the areas containing fewer songs than 6. Although the subjects were not able to filter out the correct number of tracks during a parallel playback scenario the number they detected corresponds with the number it actually was. The right plot illustrates the trend of the estimated number of tracks ordered according to the size of the presented region. Generally the participants undervalued the number of perceived tracks with decreasing divergence from the Parallel to the Sequence Mixer components. As depicted in left figure the best estimation results emerged when using the Static Sequential Mixer where 26% of the regions' size was correctly estimated.
Genre and outlier detection
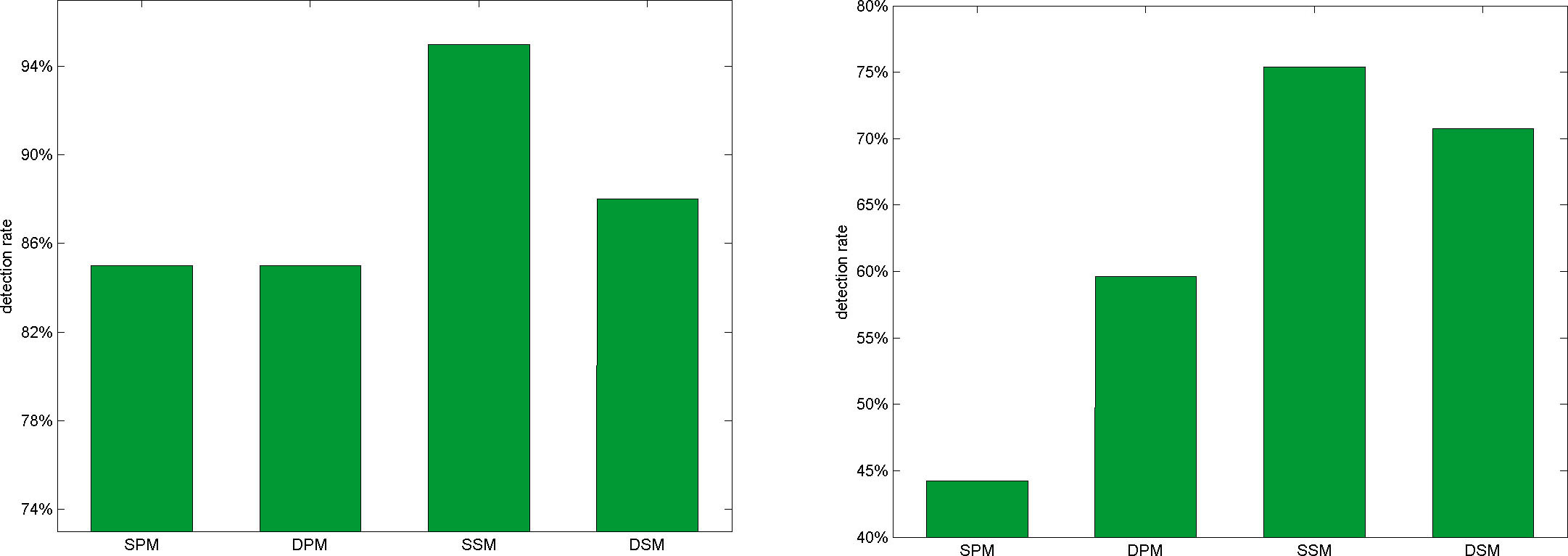
A key aim of the evaluation was to analyze the subjects' ability in detecting the main genre of the presented region. As depicted in the left figure, the subjects felt harder to correctly filter the main genre out of parallel playback than sequential playback. Interestingly, subjects who enjoyed a classical instrumental education, e.g. piano, were able to specify classical genres in more detail. They distinguished between e.g. Folklore, Choral, Church Music etc. while others simply assigned the same areas to Classic. When confronting each of these subjects to this fact after the finished evaluation process, they thought of simply assigning the area to Classic as too coarse and therefore false since all Classic is not the same. A similar effect occurred when subjects were confronted with regions which contained pieces of their preferred genre. In parallel to this effect the outlier detection highly diverged between the subjects. Subjects detected non fitting passages in areas consisting of tracks of their preferred genre more often. That indicates that subjects judge areas of their preferred genre stronger than other regions. The subjects' ability of detecting improper passages increased by switching from parallel playback to sequential playback. The right figure depicts this trend. While fewer than the half of all subjects detected a non fitting song during listening situations based on the Static Parallel Mixer, 75% of the participants thought of having perceived an improper song in a mix-down based on the Static Sequential Mixer. Sequential playback enabled the subjects recognizing the presented region in more detail which resulted in stricter judgments. So the subjects were able to perceive more passages in the presented mix-down which do not fit to the rest. As a consequence the subjects' rating of the ground-similarity decreased for sequential playback scenarios. Nearly in parallel to the decrease of the similarity score the confidence level increased.
cLynx applicability
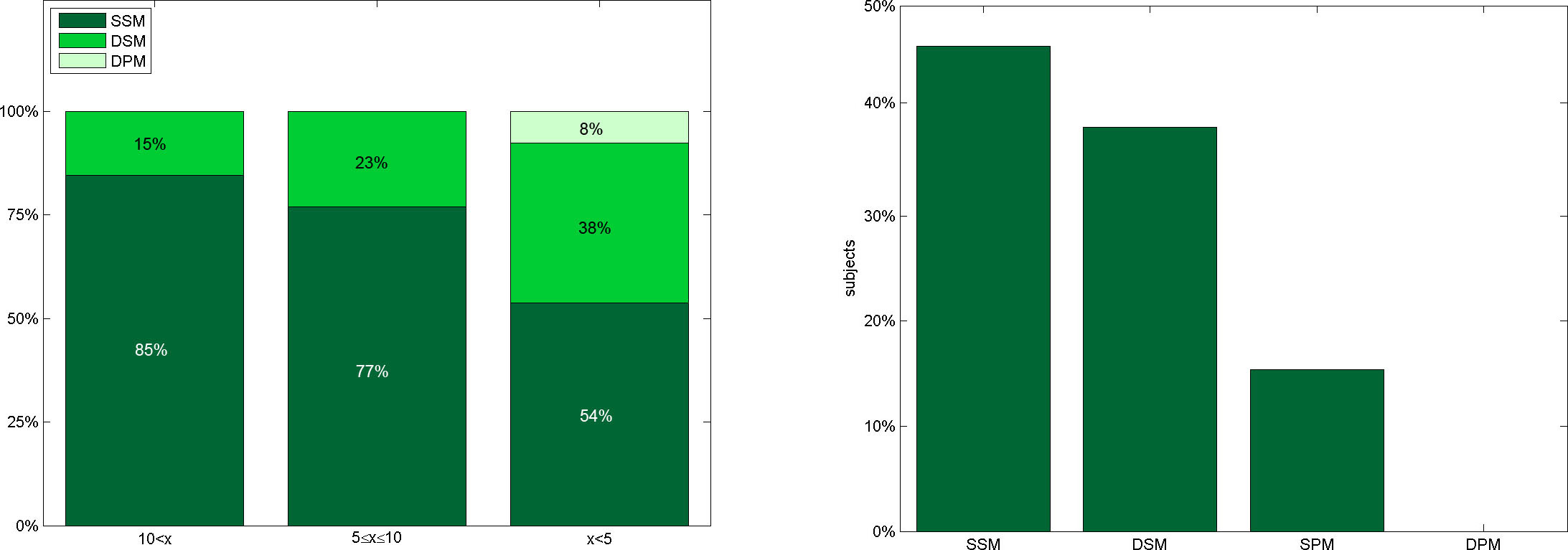
Most of the subjects seemed to be highly concentrated while listening to a mix-down performed by on of the Parallel Mixers. During the interview session the subjects felt uncertain and needed quite a long time for answering a question. In contrast, being confronted with a sequential playback scenario the subjects felt more certain during the interview situation and were able to respond within shorter time. This observation is confirmed by the left figure which illustrates the subjects' perception according to the best listening comfort for a region consisting of a defined number of x tracks. Most of the subjects consider the Static Sequential Mixer to present a mix-down with the most listening comfort. Although nearly all subjects connected the Static Parallel Mixer with the worst listening comfort, about 15% of the subjects thought that it is the most effective one. However, the right figure shows that most subjects assigned both Sequential Mixers to be most effective.
Links & Downloads
Further information about the tool, its usage and the evaluation:- Andreas Senfter: Tool Support for Acoustic Evaluation of Music Similarity, Master's Thesis, Vienna University of Technology, 2008
- Poster with overview of the tool
- cLynx tool download
- PlaySOM music clustering application
| top |
last
edited 13.03.2008 by Andreas Senfter, 29.05.2008 by Thomas Lidy
|