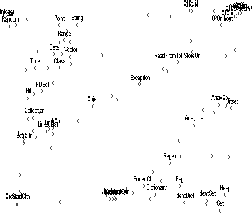The following experimental results are based on the manual pages of the NIH C++ class library collection (NIHCL) [1] as a sample text archive. The library consists of a number of classes, ranging from input/output operations to general data types and container classes. Binary vector representations were created by full-text indexing the manual pages, where 1 indicates the presence of a specific word and 0 its absence in the manual page of a specific class, with 489 distinct words being detected in the manual page collection. This resulted in input vectors of dimensionality 489 being used as input signals to both the SM as well as the SOM training process.
The left part of Figure 1 depicts the standard representation of a
![]() SOM trained with the NIHCL data.
The basic structure of the NIHCL is present in the resulting mapping with, for example, all classes concerning file input/output operations like OIOin, OIOout
being mapped onto the upper right corner of the map. Data types like Integer, Point, String
are mapped onto the upper left part.
However, we have to admit that the detection of these details of the structure and the extraction of further groupings of classes is hardly possible without profound knowledge about the classes themselves. Consider, for example, the classes Point, String and OIOofd. We have identified String to be a data type like Point, whereas OIOofd is a class dealing with input/output operations. However, String is separated from both Point and OIOofd by a single blank node.
Thus, one might come up with the erroneous perception that all three classes are of
comparable similarity.
SOM trained with the NIHCL data.
The basic structure of the NIHCL is present in the resulting mapping with, for example, all classes concerning file input/output operations like OIOin, OIOout
being mapped onto the upper right corner of the map. Data types like Integer, Point, String
are mapped onto the upper left part.
However, we have to admit that the detection of these details of the structure and the extraction of further groupings of classes is hardly possible without profound knowledge about the classes themselves. Consider, for example, the classes Point, String and OIOofd. We have identified String to be a data type like Point, whereas OIOofd is a class dealing with input/output operations. However, String is separated from both Point and OIOofd by a single blank node.
Thus, one might come up with the erroneous perception that all three classes are of
comparable similarity.
On the other hand, the right part of Figure 1 gives the corresponding AC representation. Note that the overall structure of the text archive is clearly visible from the improved output visualization provided by the AC approach. The clusters are clearly separated from each other with the distances between both nodes as well as clusters providing information about their degree of mutual similarity. For example, the input/output classes again form a very strong and strictly separated, overlapping cluster in the upper right corner.![]() It is quite obvious that the previously described misleading perception resulting from the location of Point, String and OIOofd is clarified now.
For a more detailed discussion we refer to [3].
It is quite obvious that the previously described misleading perception resulting from the location of Point, String and OIOofd is clarified now.
For a more detailed discussion we refer to [3].
The SM of the NIHCL is presented in Figure 2. The data points are arranged in a circular area with their relative locations resembling their distances in the high-dimensional space, representing a topology preserving mapping. To give an example, all classes dealing with input/output operations can be found grouped together in the upper left part of the mapping, the data types Float and Integer on the right of the mapping. However, as with the standard SOM representation, the detection of dissimilarities, i.e. cluster boundaries, is hardly possible without additional knowledge about the functionality of the classes. Although the distances between data points are not limited to a fixed grid distance, the differences in distance between related and non-related data points are too little to give clear evidence about the inclusion of data items in particular clusters. Thus, while providing information about the similarity of the input data, additional knowledge is required to detect the inherent structure of the text archive, i.e. to find the clusters and to understand their mutual relationship.
In a nutshell, the enhanced visualization using AC allows the detection of clusters, cluster boundaries and mutual similarity, and thus the overall structure of the data set, in a very intuitive way while not interfering with the robustness of the standard SOM training process. Although similar to the SM as far as the type of representation is concerned, the principles to obtain the visualization are different. While SM tries to find a location in the 2-dimensional output space for every data point, the AC visualization originates in the self-organizing process of the SOM using its abilities to cope with noise and to generalize from the given input signals. As a benefit, the AC visualization provides a clear separation of clusters. Additionally, the information concerning the overall organization of the library, i.e. different topics, is readily accessible.