Vienna
University of Technology
Institute of Software Technology and Interactive Systems
Information & Software Engineering Group
Migration of WARC Content
Introduction
Internet archives are crawling, storing and managing enormous large collections of Internet content. These archives contain essential parts of our culture heritages and need to be preserved for future generations.
While crawling and storing these objects is a complex task
itself, the Internet archives are facing a new emerging challenge concerning objects in outdated formats. Millions of
objects, such as texts, photos, videos, sounds and many
more are stored in a remarkable variety of formats within
Internet archives. The evolution of these formats danger
large amounts of archived data to become inaccessible and
not readable in the near future. Whenever the software to
render these objects and the documentation describing the
internal structure of the formats are not longer available,
these objects will become uninterpretable bit streams.
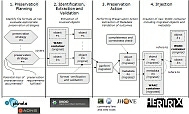
Continuous migration can help to provide access on information of harvested objects in the future. We developed a preservation workflow to migrate the content of WARC archives. A set of tools was developed to support the workflow including identification, extraction and verification of objects.
These tools allow to perform migration actions and provide
simple validation functions for migrated objects.
Publications
Stephan Strodl, Peter Paul Beran, Andreas Rauber
Migrating Content in WARC Files
Proceedings of the IWAW 2009,
Corfu, Greece, September 30 - October 1, 2009 [bib | .pdf ]
Presentation (PDF) 2 MB
Toolkit
will be published soon
Team
| Stephan Strodl |  |
Andreas Rauber |  |
| top | last edited 8.10.2009 by Stephan Strodl |